Random Variable:
In a “coin-flipping” experiment, the outcome is not known prior to the experiment, that is we cannot predict it with certainty (non-deterministic/stochastic). But we know the all possible outcomes – Head or Tail. Assign real numbers to the all possible events (this is called “sample space”), say “0” to “Head” and “1” to “Tail”, and associate a variable “X” that could take these two values. This variable “X” is called a random variable, since it can randomly take any value ‘0’ or ‘1’ before performing the actual experiment.
Obviously, we do not want to wait till the coin-flipping experiment is done. Because the outcome will lose its significance, we want to associate some probability to each of the possible event. In the coin-flipping experiment, all outcomes are equally probable (given that the coin is fair and unbiased). This means that we can say that the probability of getting Head ( our random variable X = 0 ) as well that of getting Tail ( X =1 ) is 0.5 (i.e. 50-50 chance for getting Head/Tail).
This can be written as,


Cumulative Distribution Function:
Mathematically, a complete description of a random variable is given be “Cumulative Distribution Function”- FX(x). Here the bold faced “X” is a random variable and “x” is a dummy variable which is a place holder for all possible outcomes ( “0” and “1” in the above mentioned coin flipping experiment). The Cumulative Distribution Function is defined as,


")
If we plot the CDF for our coin-flipping experiment, it would look like the one shown in the figure on your right.
The example provided above is of discrete nature, as the values taken by the random variable are discrete (either “0” or “1”) and therefore the random variable is called Discrete Random Variable.
If the values taken by the random variables are of continuous nature (Example: Measurement of temperature), then the random variable is called Continuous Random Variable and the corresponding cumulative distribution function will be smoother without discontinuities.
Probability Distribution function :
Consider an experiment in which the probability of events are as follows. The probabilities of getting the numbers 1,2,3,4 individually are






Probability Density function (PDF) and Probability Mass Function(PMF):
Its more common deal with Probability Density Function (PDF)/Probability Mass Function (PMF) than CDF.
The PDF (defined for Continuous Random Variables) is given by taking the first derivate of CDF.


For discrete random variable that takes on discrete values, is it common to defined Probability Mass Function.


The previous example was simple. The problem becomes slightly complex if we are asked to find the probability of getting a value less than or equal to 3. Now the straight forward approach will be to add the probabilities of getting the values



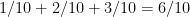
Based on the probability density function or how the PDF graph looks, PDF fall into different categories like binomial distribution, Uniform distribution, Gaussian distribution, Chi-square distribution, Rayleigh distribution, Rician distribution etc. Out of these distributions, you will encounter Gaussian distribution or Gaussian Random variable in digital communication very often.
Mean:
The mean of a random variable is defined as the weighted average of all possible values the random variable can take. Probability of each outcome is used to weight each value when calculating the mean. Mean is also called expectation (E[X])
For continuos random variable X and probability density function fX(x)

![E\left[X \right] = \int_{-\infty }^{\infty}xf_X(x)dx](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dxf_X%28x%29dx+&bg=ffffff&fg=000&s=1&c=20201002)
For discrete random variable X, the mean is calculated as weighted average of all possible values (xi) weighted with individual probability (pi)

![E\left[X \right] = \mu{_X} = \sum_{-\infty }^{\infty}x_{i}p_{i}](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX+%5Cright%5D+%3D+%5Cmu%7B_X%7D+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7Dx_%7Bi%7Dp_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)
Variance :
Variance measures the spread of a distribution. For a continuous random variable X, the variance is defined as

![var \left[X\right] = \int_{-\infty }^{\infty} \left(x - E\left[X \right] \right)^2 f_X(x) dx](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%5Cint_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28x+-+E%5Cleft%5BX+%5Cright%5D+%5Cright%29%5E2+f_X%28x%29+dx+&bg=ffffff&fg=000&s=1&c=20201002)
For discrete case, the variance is defined as

![var \left[X\right] = {\sigma^2}_X = \sum_{-\infty }^{\infty} \left( x_i - \mu_X\right)^2 p_{i}](https://s0.wp.com/latex.php?latex=var+%5Cleft%5BX%5Cright%5D+%3D+%7B%5Csigma%5E2%7D_X+%3D+%5Csum_%7B-%5Cinfty+%7D%5E%7B%5Cinfty%7D+%5Cleft%28+x_i+-+%5Cmu_X%5Cright%29%5E2+p_%7Bi%7D+&bg=ffffff&fg=000&s=1&c=20201002)
Standard Deviation (




Properties of Mean and Variance:
For a constant – “c” following properties will hold true for mean

![E\left[cX\right] = c E\left[X\right]](https://s0.wp.com/latex.php?latex=E%5Cleft%5BcX%5Cright%5D+%3D+c+E%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[X+c\right] = E\left[X\right]+c](https://s0.wp.com/latex.php?latex=E%5Cleft%5BX%2Bc%5Cright%5D+%3D+E%5Cleft%5BX%5Cright%5D%2Bc+&bg=ffffff&fg=000&s=1&c=20201002)

![E\left[c\right] = c](https://s0.wp.com/latex.php?latex=E%5Cleft%5Bc%5Cright%5D+%3D+c+&bg=ffffff&fg=000&s=1&c=20201002)
For a constant – “c” following properties will hold true for variance

![var\left[cX\right] = c^2 var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BcX%5Cright%5D+%3D+c%5E2+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[X+c\right] = var\left[X\right]](https://s0.wp.com/latex.php?latex=var%5Cleft%5BX%2Bc%5Cright%5D+%3D+var%5Cleft%5BX%5Cright%5D+&bg=ffffff&fg=000&s=1&c=20201002)

![var\left[c\right] = 0](https://s0.wp.com/latex.php?latex=var%5Cleft%5Bc%5Cright%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)
PDF and CDF define a random variable completely. For example: If two random variables X and Y have the same PDF, then they will have the same CDF and therefore their mean and variance will be same.
On the otherhand, mean and variance describes a random variable only partially. If two random variables X and Y have the same mean and variance, they may or may not have the same PDF or CDF.
Gaussian Distribution :
Gaussian PDF looks like a bell. It is used most widely in communication engineering. For example , all channels are assumed to be Additive White Gaussian Noise channel. What is the reason behind it ? Gaussian noise gives the smallest channel capacity with fixed noise power. This means that it results in the worst channel impairment. So the coding designs done under this most adverse environment will give superior and satisfactory performance in real environments. For more information on “Gaussianity” refer [1]
The PDF of the Gaussian Distribution (also called as Normal Distribution) is completely characterized by its mean (




Since PDF is defined as the first derivative of CDF, a reverse engineering tell us that CDF can be obtained by taking an integral of PDF.
Thus to get the CDF of the above given function,


Equations for PDF and CDF for certain distributions are consolidated below
| Probability Distribution | Probability Density Function(PDF) | Cumulative Distribution Function (CDF) |
|---|---|---|
Gaussian/Normal Distribution –  |
 |
 |



Reference :
[1] S.Pasupathy, “Glories of Gaussianity”, IEEE Communications magazine, Aug 1989 – 1, pp 38.
Topics in this chapter
| Random Variables - Simulating Probabilistic Systems ● Introduction ● Plotting the estimated PDF ● Univariate random variables □ Uniform random variable □ Bernoulli random variable □ Binomial random variable □ Exponential random variable □ Poisson process □ Gaussian random variable □ Chi-squared random variable □ Non-central Chi-Squared random variable □ Chi distributed random variable □ Rayleigh random variable □ Ricean random variable □ Nakagami-m distributed random variable ● Central limit theorem - a demonstration ● Generating correlated random variables □ Generating two sequences of correlated random variables □ Generating multiple sequences of correlated random variables using Cholesky decomposition ● Generating correlated Gaussian sequences □ Spectral factorization method □ Auto-Regressive (AR) model |
|---|
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) |  Digital Modulations using Python (PDF ebook) |  Digital Modulations using Matlab (PDF ebook) |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||






sir, please help me……i want to write a MATLAB script which generates N
samples from a Rayleigh distribution, and compares the sample histogram with the
Rayleigh density function. but i want to take starting point as given script
mu = 0; % mean (mu)
sig = 2; % standard deviation (sigma)
N = 1e5; % number of samples
% Sample from Gaussian distribution %
z = mu + sig*randn(1,N);
% Plot sample histogram, scaling vertical axis
%to ensure area under histogram is 1
dx = 0.5;
x = mu-5*sig:dx:mu+5*sig; % mean, and 5 standard
% deviations either side
H = hist(z,x);
area = sum(H*dx);
H = H/area;
bar(x,H)
xlim([-5*sig,5*sig])
% Overlay Gaussian density function
hold on
f = exp(-(x-mu).^2/(2*sig^2))/sqrt(2*pi*sig^2);
plot(x,f,’r’,’LineWidth’,3)
hold off
Please check this post. It has the complete code.
https://www.gaussianwaves.com/2010/02/fading-channels-rayleigh-fading-2/
Thank you….. I’ll follow. but confuse on how to start from this script….will try it.
Hello , your website is a great help for topic understanding and implementing in our project .
Sir can you plz give me the simplest PDF and CDF vs Capacity matlab code for mimo system without channel matrix ??
I mean i m using simulink platform and H matrix need not be in the code for the plot..
hoping for your fast reply at ashuu.engg@gmail.com
how can we quantify(measure) gaussian white noise in image using matlab,(donot want to use PSNR)
I am not sure about image processing. However, this link might help
http://www.mathworks.com/help/images/ref/imnoise.html
GREAT EFFORT!!! JAzak Allah kol khayr
GREAT EFFORT!!! JAzak Allah kol khayr
Ya I can deal with Random process in detail but I think divulging to finer details of Random process itself will need a separate blog.
It will be better to go in more details like stochastic process