As we have seen in the previous articles, that the estimation of a parameter from a set of data samples depends strongly on the underlying PDF. The accuracy of the estimation is inversely proportional to the variance of the underlying PDF. That is, less the variance of PDF more is the accuracy of estimation and vice versa. In other words, the estimation accuracy depends on the sharpness of the PDF curve. Sharper the PDF curve more is the accuracy.
Gradient and score :
In geometry, given any curve, the gradient (also called slope) of the curve is zero at maximum and minimum points of the curve. Gradient of a function (representing a curve) is calculated by its first derivative. The gradient of log likelihood function is called score and is used to find Maximum Likelihood estimate of a parameter.


Denoting the score as u(θ),

![u(\theta) =\frac{\partial }{\partial \theta} \left[ ln L(\theta) \right ]](https://s0.wp.com/latex.php?latex=u%28%5Ctheta%29+%3D%5Cfrac%7B%5Cpartial+%7D%7B%5Cpartial+%5Ctheta%7D+%5Cleft%5B+ln+L%28%5Ctheta%29+%5Cright+%5D+&bg=ffffff&fg=000&s=1&c=20201002)
At the MLE point, where the true value of the parameter θ is equal to the ML estimate

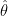


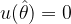
Curvature and Fisher Information :
In geometry, the sharpness of a curve is measured by its Curvature. The sharpness of a PDF curve is influenced by its variance. More the variance less is the sharpness and vice versa. The accuracy of the estimator is measure by the sharpness of the underlying PDF curve. In differential geometry, the curvature is related to second derivative of a function.
The mean of the score evaluated at ML estimate (or true value of estimate) θ is zero. This gives,

![E[u(\theta)] = 0](https://s0.wp.com/latex.php?latex=E%5Bu%28%5Ctheta%29%5D+%3D+0+&bg=ffffff&fg=000&s=1&c=20201002)
Under this regularity condition that the expectation of the score is zero, the variance of the score is called Fisher Information. That is the expectation of second derivative of log likelihood function is called Fisher Information. It measures the sharpness of the log likelihood function. More the value of Fisher Information; more is the sharpness of the curve and vice versa. So if we can calculate the Fisher Information of a log likelihood function, then we can know more about the accuracy or sensitivity of the estimator with respect to the parameter to be estimated.


The Fisher Information denoted by I(θ) is given by the variance of the score.

![\displaystyle{\begin{aligned} I(\theta) &= -var \left[ u (\theta) \right] \\ &= - E \left[ u (\theta) u^\ast (\theta) \right] \\ &= - E \left[ \frac{\partial^2 \; ln \left[ L(\theta) \right] }{\partial \theta^2} \right] \end{aligned}}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7B%5Cbegin%7Baligned%7D+I%28%5Ctheta%29+%26%3D+-var+%5Cleft%5B+u+%28%5Ctheta%29+%5Cright%5D+%5C%5C+%26%3D+-+E+%5Cleft%5B+u+%28%5Ctheta%29+u%5E%5Cast+%28%5Ctheta%29+%5Cright%5D+%5C%5C+%26%3D+-+E+%5Cleft%5B+%5Cfrac%7B%5Cpartial%5E2+%5C%3B+ln+%5Cleft%5B+L%28%5Ctheta%29+%5Cright%5D+%7D%7B%5Cpartial+%5Ctheta%5E2%7D+%5Cright%5D+%5Cend%7Baligned%7D%7D+&bg=ffffff&fg=000&s=1&c=20201002)
Here the ∗ operator indicates the operation of taking complex conjugate. The negative sign in the above equation is introduced to bring inverse relationship between variance and the Fisher Information (i.e. Fisher Information will be high for log likelihood functions that have low variance). As we can see from the above equation, that the Fisher Information is related to the second derivative (Curvature or Sharpness) of the log likelihood function. The I(θ) computed above is also called Observed Fisher Information.
Rate this article: Note: There is a rating embedded within this post, please visit this post to rate it.
For further reading
Topics in this series
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) |  Digital Modulations using Python (PDF ebook) |  Digital Modulations using Matlab (PDF ebook) |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||





