Key focus: Let’s demonstrate basics of univariate linear regression using Python SciPy functions. Train the model and use it for predictions.
Linear regression model
Regression is a framework for fitting models to data. At a fundamental level, a linear regression model assumes linear relationship between input variables ( ) and the output variable (
) and the output variable ( ). The input variables are often referred as independent variables, features or predictors. The output is often referred as dependent variable, target, observed variable or response variable.
). The input variables are often referred as independent variables, features or predictors. The output is often referred as dependent variable, target, observed variable or response variable.
If there are only one input variable and one output variable in the given dataset, this is the simplest configuration for coming up with a regression model and the regression is termed as univariate regression. Multivariate regression extends the concept to include more than one independent variables and/or dependent variables.
Univariate regression example
Let us start by considering the following example of a fictitious dataset. To begin we construct the fictitious dataset by our selves and use it to understand the problem of linear regression which is a supervised machine learning technique. Let’s consider linear looking randomly generated data samples.
import numpy as np
import matplotlib.pyplot as plt #for plotting
np.random.seed(0) #to generate predictable random numbers
m = 100 #number of samples
x = np.random.rand(m,1) #uniformly distributed random numbers
theta_0 = 50 #intercept
theta_1 = 35 #coefficient
noise_sigma = 3
noise = noise_sigma*np.random.randn(m,1) #gaussian random noise
y = theta_0 + theta_1*x + noise #noise added target
plt.ion() #interactive plot on
fig,ax = plt.subplots(nrows=1,ncols=1)
plt.plot(x,y,'.',label='training data')
plt.xlabel(r'Feature $x_1$');plt.ylabel(r'Target $y$')
plt.title('Feature vs. Target')
In this example, the data samples represent the feature  and the corresponding targets . Given this dataset, how can we predict target as a function of ? This is a typical regression problem.
and the corresponding targets . Given this dataset, how can we predict target as a function of ? This is a typical regression problem.
Linear regression
Let 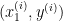 be the pair that forms one training example (one point on the plot above). Assuming there are
be the pair that forms one training example (one point on the plot above). Assuming there are  such sample points as training examples, then the set
such sample points as training examples, then the set 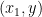 contains all the pairs
contains all the pairs 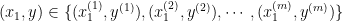 .
.
In the univariate linear regression problem, we seek to approximate the target as a linear function of the input , which implies the equation of a straight line (example in Figure 2) as given by

where, 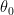 is the intercept,
is the intercept, 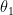 is the slope of the straight line that is sought and
is the slope of the straight line that is sought and 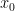 is always
is always  . The approximated target serves as a guideline for prediction. The approximated target is denoted by
. The approximated target serves as a guideline for prediction. The approximated target is denoted by 
Using all the samples from the training set , we wish to find the parameters  that well approximates the relationship between the given target samples and the straight line function .
that well approximates the relationship between the given target samples and the straight line function .
If we represent the variables  s, the input samples for
s, the input samples for  and the target samples as matrices, then, equation (1) can be expressed as a dot product between the two sequences
and the target samples as matrices, then, equation (1) can be expressed as a dot product between the two sequences

It may seem that the solution for finding is straight forward

However, matrix inversion is not defined for matrices that are not square. Moore-Penrose pseudo inverse generalizes the concept of matrix inversion to a 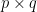 matrix. Denoting the Moore-Penrose pseudo inverse for
matrix. Denoting the Moore-Penrose pseudo inverse for  as
as 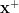 , the solution for finding
, the solution for finding  is
is

For coding in Python, we utilize the scipy.linalg.pinv function to compute Moore-Penrose pseudo inverse and estimate .
xMat = np.c_[ np.ones([len(x),1]), x ] #form x matrix
from scipy.linalg import pinv
theta_estimate = pinv(xMat).dot(y)
print(f'theta_0 estimate: {theta_estimate[0]}')
print(f'theta_1 estimate: {theta_estimate[1]}')The code results in the following estimates for , which are very close to the values used to generate the random data points for this problem.
>> theta_0 estimate: [50.66645323]
>> theta_1 estimate: [34.81080506]Now, we know the parameters of our example system, the target predictions for new values of feature can be done as follows
x_new = np.array([[-0.2],[0.5],[1.2] ]) #new unseen inputs
x_newmat = np.c_[ np.ones([len(x_new),1]), x_new ] #form xNew matrix
y_predict = np.dot(x_newmat,theta_estimate)>>> y_predict #predicted y values for new inputs for x_1
array([[43.70429222],
[68.07185576],
[92.43941931]])The approximated target as a linear function of feature, is plotted as a straight line.
plt.plot(x_new,y_predict,'-',label='prediction')
plt.text(0.7, 55, r'Intercept $\theta_0$ = %0.2f'%theta_estimate[0])
plt.text(0.7, 50, r'Coefficient $\theta_1$ = %0.2f'%theta_estimate[1])
plt.text(0.5, 45, r'y= $\theta_0+ \theta_1 x_1$ = %0.2f + %0.2f $x_1$'%(theta_estimate[0],theta_estimate[1]))
plt.legend() #plot legend
Rate this article: 

 (3 votes, average: 3.67 out of 5)
(3 votes, average: 3.67 out of 5)
References
Related topics
| [1] Introduction to Signal Processing for Machine Learning |
| [2] Generating simulated dataset for regression problems - sklearn make_regression |
| [3] Hands-on: Basics of linear regression |
Books by the author
 Wireless Communication Systems in Matlab Second Edition(PDF) (184 votes, average: 3.65 out of 5) |  Digital Modulations using Python (PDF ebook) (137 votes, average: 3.57 out of 5) |  Digital Modulations using Matlab (PDF ebook) (138 votes, average: 3.64 out of 5) |
| Hand-picked Best books on Communication Engineering Best books on Signal Processing |
||